
Every year, data breaches expose millions of people’s sensitive data, leading numerous businesses to lose millions. In fact, the average cost of a data breach thus far in 2021 is $4.24 million. Of all the breached data kinds, Personally Identifying Information (PII) is the most expensive.
As a result, data security has become a primary issue for many enterprises. Data masking has become a critical tool for many firms to secure their sensitive data.
What exactly is data masking?
Data masking, also known as data obfuscation, conceals real data by modifying information such as letters or numbers.
The primary goal of data masking is to create an alternative version of data that cannot be easily identified or reverse engineered, hence shielding sensitive data. Critically, the data will be consistent across several databases while being usable.
There are several sorts of data that may be protected via masking, however the following are some examples:
- PII: Personally identifiable information
- PHI: Protected health information
- PCI-DSS: Payment card information
- ITAR: Intellectual property
Data masking is most commonly used in non-production contexts such as software development and testing, user training, and so on—areas that do not require actual data. You may mask using a variety of ways, which we will go through in the next sections of this post.
Importance of data masking
Companies benefit from data masking in numerous ways:
- Helps businesses comply with the General Data Protection Regulation (GDPR) by removing the danger of sensitive data disclosure. As a result, data masking provides a competitive edge for many firms.
- Data is rendered worthless to cyberattackers while retaining usefulness and consistency.
- Minimize the risks associated with data sharing with third-party apps and cloud migrations.
- It eliminates the risks involved with outsourcing any project. Masking prevents data from being exploited or stolen because most firms rely only on trust when working with outsourced personnel.
Data masking types
Depending on your use case, you may choose from a variety of data masking types. The most prevalent are static and on-the-fly data masking.
static data Masking (SDM)
Static data masking is typically applied on a backup of a production database. SDM alters data to appear correct in order to accurately design, test, and train—all without disclosing the true facts. The procedure is as follows:
- Take a backup or a golden copy of the production database to a different environment.
- Remove any unnecessary data, and mask it while in stasis.
- Save the masked copy to the desired location.

Dynamic dataMasking (DDM)
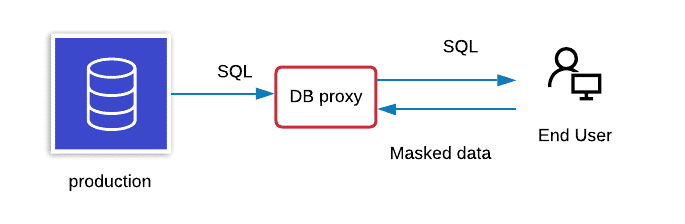
DDM occurs dynamically at run time and feeds data straight from a production system, eliminating the requirement for masked data to be recorded in another database. It is generally used to process role-based security for applications such as customer service and medical records. Hence, DDM is used in read-only environments to prevent masked data from being written back into the production system.
DDM can be implemented by utilising a database proxy, which alters queries sent to the actual database and returns masked data to the asking party. You do not need to construct a masked database in advance using DDM, but the application may run poorly.
Deterministic data Masking
The process of replacing column data with the same value is known as deterministic data masking.
For example, if your databases have numerous tables with a first name field, there might be many tables with the first name. If you change the mask from ‘Adam’ to ‘James,’ you should appear as ‘James’ not just in the masked table, but also in any connected tables. The masking will provide the same results every time.
On-the-fly data masking
On-the-fly data masking happens when data is transferred from one environment to another, such as test or development. Data masking on the fly is appropriate for businesses that:
- Continuous software deployment
- Having a lot of integrations
Because it is difficult to maintain a continuous backup copy of masked data, this method will only communicate a portion of masked data when required.
Obfuscation of statistical data
Production data can contain a variety of statistical information, which statistical data obscuration techniques can conceal. Differential privacy is a strategy for sharing information about trends in a data set without disclosing information about the data set’s real members.
Data masking methods
Let’s have a look at data masking strategies now.

Encryption
Encryption is the most complicated — and secure — method of data hiding. In this case, you employ an encryption method to conceal the data and decode it with a key (encryption key).
Encryption is more suited for production data that must be restored to its original state. But, as long as only authorised individuals have access to the key, the data will be protected. If an unauthorised entity has access to the keys, they can decrypt the data and examine the raw data. As a result, appropriate encryption key management is critical.
Scrambling
Scrambling is a simple masking method that jumbles letters and integers into a random order, disguising the original content. Although this is a straightforward approach to deploy, it can only be used to particular types of data and does not provide the level of security that you may anticipate.
For example, if an employee with ID number 934587 in one setting passes through character scrambling, it will read 489357 in another. But, anyone who recalls the initial order may be able to decipher its original value.
Nulling out
Nulling out conceals the data by assigning a null value to a data column, preventing any unauthorised user from seeing the actual data contained inside it. This is another basic strategy, however the key issues are:
- decreases data integrity
- It makes testing and development with such data more difficult.
Substitution
Substitution is the process of disguising data by replacing it with another value. This is one of the most successful data masking strategies for preserving the data’s original appearance and feel.
The replacement approach may be used to a variety of data formats. For example, using a random lookup file to disguise customer names. This can be tough to implement, but it is a very effective method of preventing data breaches.
Shuffling
Shuffling is similar to replacement in that it employs the same individual masking data column for randomised shuffling.
For example, rearranging the columns of employee names across numerous employee records. The output data appears to be correct, however it does not provide any true personal information. Unfortunately, shuffled data is vulnerable to reverse engineering if someone learns the shuffling technique.
Number & date variance
The number and data variance approach can be used to conceal sensitive financial and transaction date information.
Masking the employee salaries column with the employee pay variance, for example, will display the wages of the highest and lowest paid employees. You may confirm the data set’s meaning by adding a +/- 10% variance to all wages in the collection.
Date Aging
Based on the set data masking policy and an allowable date range, this masking approach either raises or reduces a date field. For example, reducing the date of birth by 1000 days would result in the date ‘1-Jan-2021′ becoming ’07-Apr-2018.’
Best practises are obscured by data.
Are you ready to begin hiding data? These are some excellent practises to keep in mind.
Identify the sensitive data
Identify and categorise the following before masking any data:
- Location of sensitive data (s)
- Person(s) authorised to see them
Their usage
Masking is not required for every data element in a corporation. Rather, completely identify all sensitive data in both production and non-production situations. Depending on the intricacy of the data and the organisational structure, this might take a long time.
Define your data masking method stack
Because data differs considerably, it is impractical for big enterprises to employ a single masking technique throughout the whole enterprise. Furthermore, the solution you use may need you to adhere to certain internal security regulations or fulfil budgetary constraints. You may need to refine your masking approach in some circumstances.
Consider all of these considerations while selecting the correct collection of approaches. Keep them in sync to guarantee that data of the same type uses the same mechanism to maintain referential integrity.
Protect your data masking techniques
Masking strategies and related data are just as important as sensitive data. The replacement approach, for example, can employ a lookup file for substitution. If this lookup file ends up in the wrong hands, it has the potential to divulge the original data set.
Businesses should set the necessary criteria to ensure that only authorised individuals have access to the masking algorithms.
Make masking repeatable
Changes to an organisation or a specific project or product might cause data to alter over time. Avoid starting from scratch every time. Instead, make masking a repeatable, simple, and automated procedure that you can use whenever sensitive data changes.
Create a complete data masking process
Companies must have a comprehensive procedure that covers the following steps:
- Recognizing sensitive information
- Using the proper data masking method
- Constantly auditing to verify data masking is functioning properly.
Data masking is essential
Several companies rely on data masking to secure sensitive data by hiding its authenticity.
Source: Shanika Wickramasinghe